The Tale of Two “Negative” Studies
Two recent trials reported nonsignificant results. There is oodles to learn from the different ways they were analyzed and reported.

This is a story of two medical studies. One enhances faith in the scientific process. The other induces cynicism.
The specifics of the interventions—one for atrial fibrillation (AF), the other for heart failure—are not the point. The point is the opposite ways in which scientists interpreted and presented the results.
Chapter 1:
The DECAAF II trial tested two approaches to the ablation of patients with persistent AF.
One background point: patients with persistent AF can develop islands of scar tissue (fibrosis) within the atria. Scar in the heart increases the odds of arrhythmias because it disrupts the flow of electricity—like rocks in a stream. The DECAAF II authors had previously shown that the degree of scar in the atria, measured with MRI, correlated with AF recurrences after ablation.
The idea behind DECAAF II was that an MRI-guided ablation strategy, wherein doctors ablate the islands of scar plus do basic PVI, would lead to greater success than PVI alone.

The trial enrolled more than 800 patients from 44 centers across the globe. The primary endpoints were simple: AF recurrences and safety outcomes.
The MRI-guided approach did not lead to a significantly reduced rate of AF. Worse, patients in the MRI-guided ablation group had more major complications (9 vs 0), including 6 strokes vs none in the standard arm.
Here is what the authors wrote in the journal JAMA:
Among patients with persistent AF, MRI-guided fibrosis ablation plus PVI, compared with PVI catheter ablation only, resulted in no significant difference in atrial arrhythmia recurrence.
Findings do not support the use of MRI-guided fibrosis ablation for the treatment of persistent AF.
Notice the clarity. Many of the authors of this trial, including the lead author Nassir Marrouche, were proponents of this strategy. They believed it would work. I would guess some of them loved the MRI-based strategy.
But when it didn’t pass muster in the randomized controlled trial, they did not waver. They concluded with those two clear sentences.
Chapter 2:
Now let me show another study that also had a nonsignificant primary endpoint. But the authors took a vastly different approach to presenting the data and making conclusions.
The GUIDE-HF trial studied the use of a paper-clip sized monitor (called CardioMEMS) placed via an invasive procedure into the pulmonary artery of patients with heart failure.
The idea is that the device measures and transmits data on heart function to doctors—who can then use the data to better adjust medications.
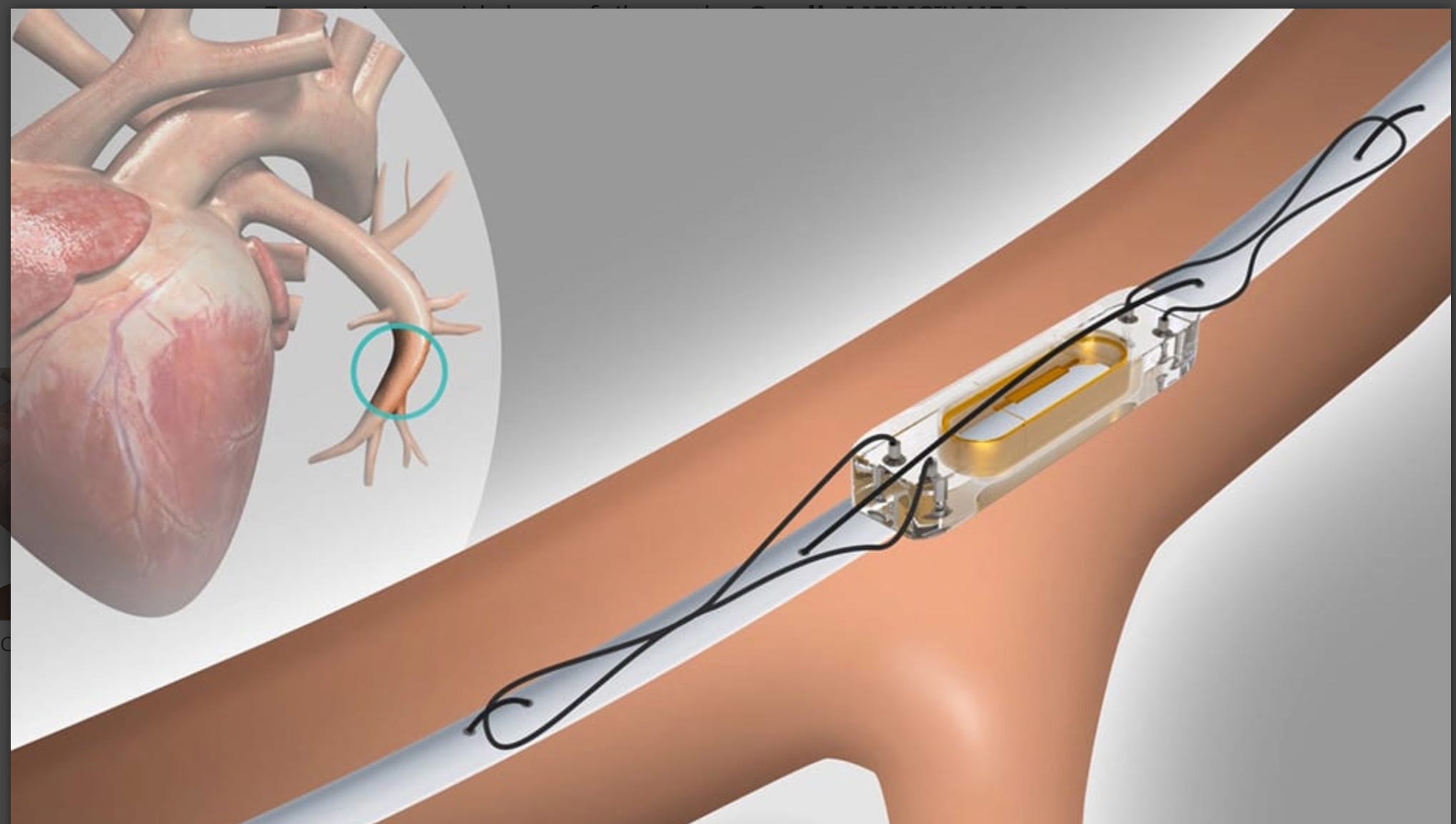
The current strategy of managing patients with heart failure is quite basic: we use symptoms, daily weights and the presence of swelling in the legs or abdomen. The theory of CardioMEMS is having wirelessly transmitted data on heart function has to be better than such mundane observations.
And there were hints that it might work. The CHAMPION trial, published in 2014, found that patients in the group that used the invasive data had lower rates of readmissions to the hospital for heart failure compared to those managed without the internal data. But adoption of the device was low because the trial enrolled a narrow population of patients, and we had no idea whether or not the reduction in heart failure admissions reduced total admissions.
GUIDE-HF tested the device in a much broader group of patients with heart failure. It measured a primary endpoint of three things: death due to cardiac causes, an urgent heart failure visit or a heart failure hospitalization.
The main results were that 253 primary outcome events occurred in the treatment arm vs 289 primary outcome events in the control arm. The relative risk reduction was 12% and we express this in a hazard ratio of 0.88. The 95% confidence intervals ranged from 0.75 ( a 25% reduction) to 1.05 (a 5% increase). The p-value, which calculates the surprise value of this data if you assume there were no differences, was 0.16; and the accepted threshold for significance is lower at 0.05.
The upshot is that because the confidence intervals included a risk increase and because the p-value is well above the threshold, GUIDE HF is considered a non-significant trial. The paper-clip sized monitor did not pass our accepted regulatory standard.
Did the authors write a clear conclusion like the DECAAF II authors? No, they did not.
Instead, they did something perplexing: they re-analyzed the data using different subsets of data. Their excuse for doing so was that the COVID-19 pandemic altered trial follow-up in about one-fourth of patients.
Three-fourths of the patients had finished follow-up before the pandemic and when they looked at this group only, there were fewer primary events in the CardioMEMS arm and the difference barely made the p-value threshold at 0.049.
Here is a screenshot of their conclusion with the highlighted caveat.

In addition to the fact that you can’t take negative results of an experiment and analyze in different ways to find a positive outcome, there were other problems with the interpretation. I laid these out in a column here. For the purposes of Stop and Think, I won’t get into the other details. But in that column I show how a deeper look into the pre- and during-COVID-19 subsets actually strengthens confidence in the nonsignificant results of the main analysis.
The authors write that the pre-COVID analysis was done in consultation with regulators, including FDA. But this does not make it right. You might also think a medical journal with its peer-reviewers would not allow such a dubious analysis. Nope. The Lancet, one of the top medical journals, published it.
Worse, FDA expanded the indication for the device—which costs about $20k—and now renders a million more patients eligible for the device. Do that math.
One more screenshot. The abbreviations are the authors.

Summary — What a contrast!
DECAAF II authors formed a plausible theory of improving the results of AF ablation. They tested it in a proper trial. It did not work. In their discussion they speculated as to why it might not have worked. And they may refine the technique and re-test it. But in their conclusions they did not hedge—or split up the data to do other analyses.
DECAAF II authors enhanced trust in science.
GUIDE-HF authors also had a plausible theory of improving the management of heart failure patients. They tested the device in a proper trial and the main results did not pass the regulatory standard. But instead of stating that clearly, they did an after-the-fact analysis and found a barely positive result.
What were the effects of that?
When regulators approve the use of a $20k device in up to a million more people based on a trial that failed to show benefit in its main analysis, it not only creates waste in an already wasteful US healthcare system, it also blankets the science of discovery with a veneer of cynicism.
Cynicism is terrible because innovation—even that driven by profit motive—can bring us great things. I hate the idea of being tempted to be cynical about medical science.
My final question is for my colleagues: will you use an expensive invasive device based on this evidence?
Many thanks for your honest assessment of these studies. I'm not a medical person (and don't play one in any of my life formats.......). As a reasonably good critical thinker, I'm struck by how much obfuscation and biassed "science" we're seeing of late. Or has it always been this way?
The COVID mess has brought much of this to light for me. It certainly seems like the FDA/CDC are not promoting open and honest science. What surprises me is how easily professionals in the medical field so willingly just follow along. Too much big $$$ at play?
Short answer. NO. Statistical manipulation and skulduggery to find a desired result destroys credibility of medical research.